Technical
Upsert with conditional data update? oh my(sql)
Found an interesting scenario from an app using mysql where:
- need to perform upsert (insert or update when same data/keys already exists)
- need to do the upsert in bulk
- when performing the update, also need to only update the data based on certain condition (e.g. based on timestamp)
After some googling and SO-ing, managed to create the sample sql snippet to get the above done.
The sample upsert_table definition:
create table upsert_table ( id int(11) unsigned not null primary key auto_increment, unkey1 varchar(10) not null, unkey2 varchar(10) not null, val1 varchar(100) not null, val2 varchar(100) not null, lastmodified int(11) unsigned, unique(unkey1, unkey2) )
Note: unlike in some databases where the upsert can be done based on a certain condition, in mysql, the upsert is determined by the unique index or primary key, refer to the excerpt from the official documentation:
If you specify an ON DUPLICATE KEY UPDATE clause and a row to be inserted would cause a duplicate value in a UNIQUE index or PRIMARY KEY, an UPDATE of the old row occurs.
Let’s populate the table with the following data:
+----+--------+--------+-----------+----------+--------------+ | id | unkey1 | unkey2 | val1 | val2 | lastmodified | +----+--------+--------+-----------+----------+--------------+ | 1 | A | 11 | Meeting A | room 1-1 | 1503662401 | | 2 | B | 22 | Meeting B | room 2-2 | 1503662402 | | 3 | C | 33 | Meeting C | room 3-3 | 1503662403 | | 4 | D | 44 | Meeting D | room 4-4 | 1503662404 | | 5 | E | 55 | Meeting E | room 5-5 | 1503662405 | +----+--------+--------+-----------+----------+--------------+
Execute the bulk upsert as well as conditional data update:
insert into upsert_table
(unkey1, unkey2, val1, val2, lastmodified)
values
('A', '11', 'Updated Meeting A', 'room 1-10', UNIX_TIMESTAMP('2017-08-25 20:00:11')),
('B', '22', 'Should not update Meeting B', 'room 2-20', UNIX_TIMESTAMP('2017-08-25 19:00:02')),
('F', '66', 'New Meeting F', 'room 6-6', UNIX_TIMESTAMP('2017-08-25 20:00:06'))
on duplicate key update
val1 = if (lastmodified < values(lastmodified), values(val1), val1),
val2 = if (lastmodified < values(lastmodified), values(val2), val2),
lastmodified = if (lastmodified < values(lastmodified), values(lastmodified), lastmodified);
Here’s the final result:
+----+--------+--------+-------------------+-----------+--------------+ | id | unkey1 | unkey2 | val1 | val2 | lastmodified | +----+--------+--------+-------------------+-----------+--------------+ | 1 | A | 11 | Updated Meeting A | room 1-10 | 1503662411 | | 2 | B | 22 | Meeting B | room 2-2 | 1503662402 | | 3 | C | 33 | Meeting C | room 3-3 | 1503662403 | | 4 | D | 44 | Meeting D | room 4-4 | 1503662404 | | 5 | E | 55 | Meeting E | room 5-5 | 1503662405 | | 6 | F | 66 | New Meeting F | room 6-6 | 1503662406 | +----+--------+--------+-------------------+-----------+--------------+
What just happened?
- row with key “A”-“11” was updated because data with same unique key existed and new timestamp is greater than existing timestamp
- row with key “B”-“22” was NOT updated although data with same unique key existed because the new timestamp is lesser than existing timestamp (actually it’s just updated with the existing value if you look the query closely)
- row with key “F”-“66” should be inserted because data with same unique key does not exist
Not forgetting to thank to the references below
– https://dev.mysql.com/doc/refman/5.7/en/insert-on-duplicate.html
– https://stackoverflow.com/questions/32777081/bulk-insert-and-update-in-mysql
– https://thewebfellas.com/blog/conditional-duplicate-key-updates-with-mysql
Get the full gist from -> https://gist.github.com/bembengarifin/9ea92f16eeb308ad5675fdc0995f4d1b
.NET Core, Testing, Testing 1, 2, 3!
In the previous post, I created a simple file processor app with .NET Core.
In this post, I want to share how seamlessly unit testing can be done with .NET Core as well.
For unit testing, I have referenced the followings from NuGet:
1. Unit Test Framework – MSTest
2. Mocking Framework – Moq
3. BDD Style Unit Test – TestStack.BDDfy
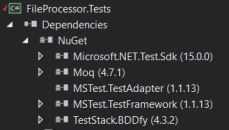
And by following the separation of concerns design principle, the application is split into separate components as per below:
1. Processor = the main component that has the brain/logic to achieve the task by using different components
2. IDataRepository = the component to retrieve the data/files
3. ILockManager = the component to perform the synchronization
4. ILogger = the component to do loggings
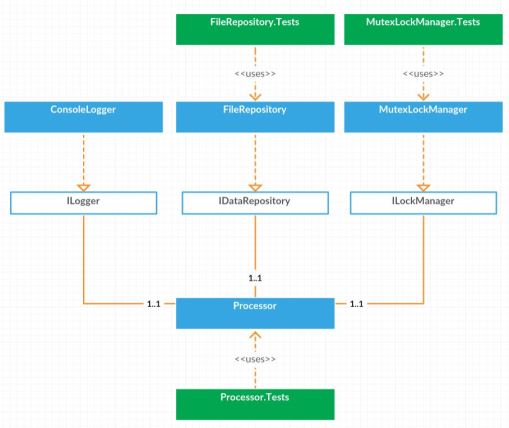
PS: I created the above diagram online with Creately. Pretty nice, isn’t it!
Unit testing then became quite straight forward. For example, the unit test code snippet below was taken from the Processor.Tests class where the unit tests are structured by the Given When Then (BDD style) and BDDfy framework will execute the tests by the convention.
[TestClass]
[Story(
AsA = "As a File Processor Instance",
IWant = "I want to retrieve files",
SoThat = "So that there is no race condition where multiple file processors are picking up same files")]
public abstract class File_Processor_Processes_Items
{
// Parts of the unit tests have been removed, pls refer to the full unit test at https://github.com/bembengarifin/FileProcessor/blob/master/FileProcessor.Tests/Processor.Tests.cs
[TestMethod]
public void ExecuteTestScenario()
{
// the generic type is passed to explicitly bind the story to the base type
this.BDDfy<File_Processor_Processes_Items>(this.GetType().Name.Replace("_", " "));
}
[TestClass]
public class Lock_Is_Available_Immediately : File_Processor_Processes_Items
{
public void Given_Lock_Is_Not_Being_Held_By_Any_Other_Process()
{
// setup the expectation for data repository
_mockedDataRepo.Setup(x => x.GetNextItemsToProcess(_itemsToFetchAtATime));
// setup the expectation for the lock manager, with the return true when being called
IEnumerable<IDataObject> result;
Func<IEnumerable<IDataObject>> get = () => _mockedDataRepo.Object.GetNextItemsToProcess(_itemsToFetchAtATime);
_mockedLockManager.Setup(x => x.TryLockAndGet(_getFileLockKey, _lockMsTimeout, get, out result)).Returns(true);
}
public void When_The_Run_Process_Is_Executed()
{
_processor.RunProcess();
}
public void Then_Lock_Manager_Was_Called()
{
_mockedLockManager.Verify();
}
public void And_Data_Should_Be_Retrieved_For_Further_Processing()
{
_mockedDataRepo.Verify();
}
}
}
And here’s the nice HTML output results (note the report file path where it’s generated)
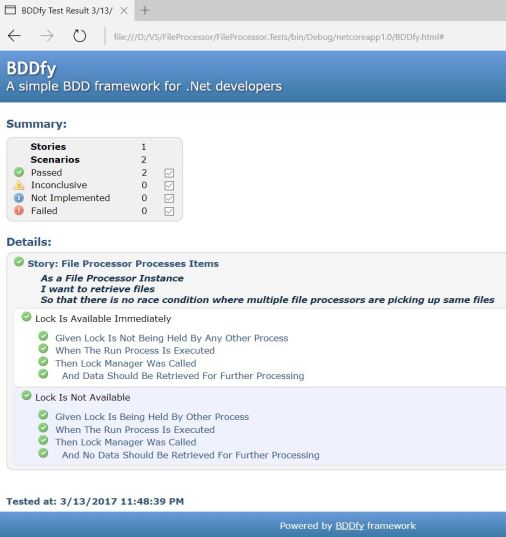
There’s no more excuse not to do the unit testing with .NET Core, isn’t it?
Happy Unit Testing :)
Link to the unit test/project.
Hello “.NET Core” World!
Recently I had a chance to look into an application that processes incoming data in a form of files.
I found it’s quite a good time to have a play around with the .NET Core as I only have heard about it so far till now.
So what are the scenarios to cover:
1. The application needs to fetch x number of files at a time
2. The application needs to be able to perform synchronization for the fetch, as we may either run multiple processes and/or multiple threads
I managed to complete the code simply by coding the same exact way (linq, cw, read file, etc) as I would normally do for .Net Framework app.
The only difference at the end is the output for .Net Core console app is apparently a dll rather an exe as in .Net Framework Console app.
The execution is by calling a dotnet[.exe] [dll name]
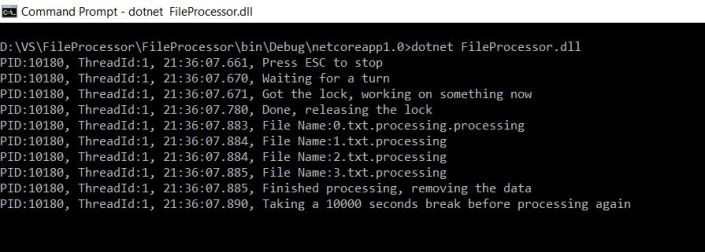
It’s been fun to get that kind of small app running without any fuss!
Here’s the link to the project/code.
Generic List converter to multidimensional (2D) string array (for excel data population)
This post is still related to the excel data population that I posted 2 weeks back where I concluded that the most performant way for the data population is using multidimensional string array (multi cells & rows).
Let’s first take a look at the SampleObject class that we use to populate the data into excel
class SampleObject
{
public string A { get; set; }
public string B { get; set; }
public string C { get; set; }
public string D { get; set; }
public string E { get; set; }
}
Now in the previous post, the data population is being done “statically” compiled, means it only supports for that exact SampleObject type/class.
static void PopulateItemsWithMultiCellsAndRowsMethod(Worksheet worksheet, IList<SampleObject> items)
{
LogFormat("Start populating {0} rows using multi cells and rows method", items.Count.ToString());
var stringArray = new string[items.Count, 5];
for (int i = 0; i < items.Count; i++)
{
var item = items[i];
var rowIndex = i + 1;
stringArray[i, 0] = item.A;
stringArray[i, 1] = item.B;
stringArray[i, 2] = item.C;
stringArray[i, 3] = item.D;
stringArray[i, 4] = item.E;
}
var r = worksheet.get_Range(string.Format("A{0}:E{1}", 1, items.Count));
r.Value = stringArray;
DisposeCOMObject(r);
}
The above will work just fine until there are other “SampleObjectX”s that need to be supported, so it will be more convenient if we can “dynamically” do this for any given objects.
One obvious answer will be using Reflection but there is also another alternative which is generating dynamic methods using Expression Tree. There are pros and cons between the 2 options above (nicely explained by this post).
In below code snippet, I summarized the 3 approaches
1. Statically
string[,] ConvertTo2DStringArrayStatically(IList<SampleObject> items)
{
var stringArray = new string[items.Count, 5];
for (int i = 0; i < items.Count; i++)
{
var item = items[i];
stringArray[i, 0] = item.A;
stringArray[i, 1] = item.B;
stringArray[i, 2] = item.C;
stringArray[i, 3] = item.D;
stringArray[i, 4] = item.E;
}
return stringArray;
}
2. With reflection
string[,] ConvertTo2DStringArrayWithReflection<T>(IList<T> items)
{
var props = typeof(T).GetProperties();
var stringArray = new string[items.Count, props.Length];
for (int i = 0; i < items.Count; i++)
{
var item = items[i];
for (int iProp = 0; iProp < props.Length; iProp++)
{
stringArray[i, iProp] = props[iProp].GetValue(item).ToString();
}
}
return stringArray;
}
3. With Expression Tree (no cache is added intentionally for brevity purpose)
Func<IList<T>, string[,]> ConvertTo2DStringArrayWithExpressionTree<T>()
{
var t = typeof(T);
var tProperties = t.GetProperties();
var statements = new List<Expression>();
var listInputParameter = Expression.Parameter(typeof(IList<T>));
var itemPropertiesCount = Expression.Constant(tProperties.Length);
var rowCountExpression = Expression.Property(listInputParameter, typeof(ICollection<T>), "Count");
var arrayIndexVariable = Expression.Variable(typeof(int));
var currentItem = Expression.Variable(t);
statements.Add(Expression.Call(typeof(Console).GetMethod("WriteLine", new Type[] { typeof(string), typeof(string) })
, Expression.Constant("Converting {0} rows with expression tree")
, Expression.Call(rowCountExpression, typeof(object).GetMethod("ToString"))));
// Initialize string array based on the items row count and the
var stringArrayVariable = Expression.Variable(typeof(string[,]));
var newArrayExpression = Expression.NewArrayBounds(typeof(string), rowCountExpression, itemPropertiesCount);
var initializeArray = Expression.Assign(stringArrayVariable, newArrayExpression);
statements.Add(initializeArray);
// Prepare item assignments here as it requires loop on the properties which can't be done inline
var itemStatements = new List<Expression>();
itemStatements.Add(Expression.Assign(currentItem, Expression.Property(listInputParameter, "Item", arrayIndexVariable)));
for (int pIndex = 0; pIndex < tProperties.Length; pIndex++)
{
var propExpression = Expression.Property(currentItem, tProperties[pIndex]);
itemStatements.Add(Expression.Assign(Expression.ArrayAccess(stringArrayVariable, new List<Expression> { arrayIndexVariable, Expression.Constant(pIndex) }), propExpression));
}
itemStatements.Add(Expression.PostIncrementAssign(arrayIndexVariable));
// iterate the items
var label = Expression.Label();
var forLoopBody = Expression.Block(
new[] { arrayIndexVariable }, // local variable
Expression.Assign(arrayIndexVariable, Expression.Constant(0)), // initialize with 0
Expression.Loop(
Expression.IfThenElse(
Expression.LessThan(arrayIndexVariable, rowCountExpression), // test
Expression.Block(new[] { currentItem }, itemStatements), // execute if true
Expression.Break(label)) // execute if false
, label));
statements.Add(forLoopBody);
// return statement
statements.Add(stringArrayVariable);
var body = Expression.Block(stringArrayVariable.Type, new[] { stringArrayVariable }, statements.ToArray());
var compiled = Expression.Lambda<Func<IList<T>, string[,]>>(body, listInputParameter).Compile();
return compiled;
}
the expression tree “body” in DebugView
.Block(System.String[,] $var1) {
.Call System.Console.WriteLine("Converting {0} rows with expression tree", .Call ($var2.Count).ToString());
$var1 = .NewArray System.String[$var2.Count,5];
.Block(System.Int32 $var3) {
$var3 = 0;
.Loop {
.If ($var3 < $var2.Count) {
.Block(ExcelDataPopulator.SampleObject $var4) {
$var4 = $var2.Item[$var3];
$var1[$var3,0] = $var4.A;
$var1[$var3,1] = $var4.B;
$var1[$var3,2] = $var4.C;
$var1[$var3,3] = $var4.D;
$var1[$var3,4] = $var4.E;
$var3++
}
} .Else {
.Break #Label1 { }
}
}
.LabelTarget #Label1:
};
$var1
}
From the performance benchmark side,
var sw = Stopwatch.StartNew();
var items = Enumerable.Range(1, 1000000).Select(i => new SampleObject { A = "A" + i, B = "B" + i, C = "C" + i, D = "D" + i, E = "E" + i }).ToList();
string[,] stringArray = null;
LogFormat("Initialized {0} rows, {1} ms", items.Count.ToString(), sw.ElapsedMilliseconds.ToString());
sw.Restart();
for (int i = 0; i < 10; i++)
stringArray = ConvertTo2DStringArrayStatically(items);
LogFormat("Convert with statically is completed in {0} ms", sw.ElapsedMilliseconds.ToString());
sw.Restart();
for (int i = 0; i < 10; i++)
stringArray = ConvertTo2DStringArrayWithReflection(items);
LogFormat("Convert with reflection is completed in {0} ms", sw.ElapsedMilliseconds.ToString());
sw.Restart();
for (int i = 0; i < 10; i++)
stringArray = ConvertTo2DStringArrayWithExpressionTree<SampleObject>()(items);
LogFormat("Convert with expression tree is completed in {0} ms", sw.ElapsedMilliseconds.ToString());
// log output:
//Initialized 1,000,000 rows, 1,747 ms
//Convert with statically is completed in 1,077 ms
//Convert with reflection is completed in 10,915 ms
//Convert with expression tree is completed in 1,617 ms
So conclusions:
- statically will always be the most performant but maintainability is a bit of a challenging if we have many objects/types to support.
- reflection is 10x slower but the code is much simpler
- dynamic method via expression tree is having more code to build the expressions but the performance is only slightly slower than statically compiled option.
There are couple of more options available that I didn’t cover above:
- Code generation using class metadata/reflection
- Reflection.Emit
Full source code is available at https://github.com/bembengarifin/ExcelDataPopulator)
Generate (lazy and infinite) list of excel column names sequence
While I was looking into the excel data population, I found that in order to populate the data with different column size (fields) into excel, I will definitely require some list of excel column names for this purpose.
// "A" = column index (int) to populate from
// "E" = column index (int) based on A above + total fields count
worksheet.get_Range("A1:E10000");
The interesting here is how the excel column names sequence is not the same as number sequence (below)

There are various ways described here which will get the job done, and excel is limited to 16,384 columns (last column name is XFD)
However, I’m keen to create a function which can generate “unlimited” sequence. I got this idea from the recent Functional Programming course where Haskell has this infinite list and lazy evaluation and in C#, this laziness can be represented with IEnumerable and yield.
Here’s the function:
/// <summary>
/// This is an infinite list of excel kind of sequence, the caller will be controlling how much of data that it really requires
/// The method signature is very similar to Enumerable.Range(start, count)
///
/// Whereas, the other 2 optionals parameters are not for the caller, they are only for internal recursive call
/// </summary>
/// <param name="start">The value of the first integer in the sequence.</param>
/// <param name="count">The number of sequential integers to generate.</param>
/// <param name="depth">NOT TO BE SPECIFIED DIRECTLY, used for recursive purpose</param>
/// <param name="slots">NOT TO BE SPECIFIED DIRECTLY, used for recursive purpose</param>
/// <returns></returns>
IEnumerable<int[]> Iterate(int start, int count, int depth = 1, int[] slots = null)
{
if (slots == null) slots = new int[depth];
for (int i = start; i < start + count; i++)
{
slots[depth - 1] = i;
if (depth > 1)
foreach (var x in Iterate(start, count, depth - 1, slots)) yield return x;
else
yield return slots.Reverse().ToArray();
}
if (slots.Length == depth)
foreach (var x in Iterate(start, count, depth + 1, null)) yield return x;
}
Any of the code below will generate the same column names from “A” to “XFD” in 30ms on my laptop (i7 2.5Ghz Quad core)
foreach (var item in Iterate(0, 26).Take(16384))
{
var columnName = string.Join("-", item.Select(x => (char)(x + 65)).ToArray()).Trim();
Debug.WriteLine(columnName);
}
foreach (var item in Iterate(65, 26).Take(16384))
{
var columnName = string.Join("-", item.Select(x => (char)x).ToArray()).Trim();
Debug.WriteLine(columnName);
}
And the most interesting “infinite” test :)
var i = 0;
foreach (var item in Iterate(0, 26))
{
var columnName = string.Join("-", item.Select(x => (char)(x + 65)).ToArray()).Trim();
Debug.WriteLine("#{0} = {1}", i, columnName);
i++;
}
/*
#0 = A
.....
#16383 = X-F-D (excel limit)
.....
#133866109 = K-F-X-J-T-N
.....
#321272406 = A-A-A-A-A-A-A
.....
*/
Ways to populate data into excel via C# and excel interop (with performance comparison)
Few days ago I was looking into some excel automation code where I need to fetch the data from the back end and then write/populate the data into excel.
There are 3 ways that we can populate the data into excel via excel interop.
1. Single cell
var r1 = worksheet.get_Range("A1"); // single cell
r1.Value = "A1";
2. Multi cells for 1 row
var r2 = worksheet.get_Range("A2:C2"); // multi cells in 1 row
r2.Value = new[] { "A2", "B2", "C2" };
3. Multi cells & rows
var r3 = worksheet.get_Range("A3:C4"); // multi cells & rows
r3.Value = new string[,] { { "A3", "B3", "C3" }, { "A4", "B4", "C4" } }; ;
As the work is related to large volume of data (100K rows), I looked further into the options above to find the most performant one.
So I came up with a list of 100k rows very simple object (5 properties), gave each option a run, and got the stats:
Start populating 100,000 rows using single cell method Populate data completed in 196,206 ms Start populating 100,000 rows using multi cells (per 1 row) method Populate data completed in 43,039 ms Start populating 100,000 rows using multi cells and rows method Populate data completed in 1,028 ms
Sample output

Quite staggering differences between the options and I’m quite impressed with the excellent performance of the multi cells/rows option.
Included the code snippets below for quick view (full source code is also available at https://github.com/bembengarifin/ExcelDataPopulator)
static void PopulateItemsWithSingleCellMethod(Worksheet worksheet, IList<SampleObject> items)
{
LogFormat("Start populating {0} rows using single cell method", items.Count.ToString());
for (int i = 0; i < items.Count; i++)
{
var item = items[i];
var rowIndex = i + 1;
var r1 = worksheet.get_Range("A" + rowIndex); r1.Value = item.A; DisposeCOMObject(r1);
var r2 = worksheet.get_Range("B" + rowIndex); r2.Value = item.B; DisposeCOMObject(r2);
var r3 = worksheet.get_Range("C" + rowIndex); r3.Value = item.C; DisposeCOMObject(r3);
var r4 = worksheet.get_Range("D" + rowIndex); r4.Value = item.D; DisposeCOMObject(r4);
var r5 = worksheet.get_Range("E" + rowIndex); r5.Value = item.E; DisposeCOMObject(r5);
}
}
static void PopulateItemsWithMultiCellsOneRowMethod(Worksheet worksheet, IList<SampleObject> items)
{
LogFormat("Start populating {0} rows using multi cells (per 1 row) method", items.Count.ToString());
for (int i = 0; i < items.Count; i++)
{
var item = items[i];
var rowIndex = i + 1;
var r = worksheet.get_Range(string.Format("A{0}:E{0}", rowIndex));
r.Value = new[] { item.A, item.B, item.C, item.D, item.E };
DisposeCOMObject(r);
}
}
static void PopulateItemsWithMultiCellsAndRowsMethod(Worksheet worksheet, IList<SampleObject> items)
{
LogFormat("Start populating {0} rows using multi cells and rows method", items.Count.ToString());
var stringArray = new string[items.Count, 5];
for (int i = 0; i < items.Count; i++)
{
var item = items[i];
var rowIndex = i + 1;
stringArray[i, 0] = item.A;
stringArray[i, 1] = item.B;
stringArray[i, 2] = item.C;
stringArray[i, 3] = item.D;
stringArray[i, 4] = item.E;
}
var r = worksheet.get_Range(string.Format("A{0}:E{1}", 1, items.Count));
r.Value = stringArray;
DisposeCOMObject(r);
}
Setting up notepad++ for haskell programming
I have been playing with Haskell for the past few weeks now, since I enrolled in “Introduction to Functional Programming” at edX.org. It’s quite interesting and challenging at the same time for me as I have always been doing imperative programming such as C#, so it does take some efforts for me to digest the language.
I started with GHCi where I can interactively play with haskell expressions then tried (Linux) VI editor but I found opening 2 windows/tabs (1 for editing and 1 for compile/run) was just somewhat inconvenience.
After searching and trying couple of other code editors for a while, I finally stick with Notepad++, because it allows 1 single shortcut/click to compile/run the haskell code (sweet!). There are IDEs as well but I didn’t try much as code editor is quite sufficient for me now.
This is pretty useful as what you can see below, I can just press Ctrl+F6 which will open a console + run the main + terminate the app in 1 go. It’s up to us how we want to run the app, for example “ghci -XHaskell98 helloWorld.hs” will load the module and display the GHCi in the console for further user interactive input.

1 other notable IDE that is really good is the FP Haskell Centre which is online and can even be integrated to github.
protobuf-net v2 performance test
This is a continuation from my previous post of Run time initialisation of protobuf-net v2 without annotation
I listed couple of ways to use protobuf-net v2:
- annotation on the class (ProtoContractAttribute) and property (ProtoMemberAttribute)
- annotation only on the class (ProtoContractAttribute) with ImplicitFields named parameter
- run time registration using the default model (RuntimeTypeModel.Default)
- run time registration with separate type model which supports run time compilation (from the method description -> Fully compiles the current model into a static-compiled serialization dll)
- precompiled serializer (this is not really a different method, but a further optimisation to the 1st and 2nd options above)
Based on the list above, I created some performance tests using a class defined with 150+ properties (mixed with string, custom classes) to make it closer to real life entity that I have in the project.
And below is the statistics produced by the test for different collection sizes, ordered by the most “efficient” ones to regular binary serialization for comparison purpose.
Conclusions:
- Performance : Precompiled serializer seems to be the notable performant option, although as you can see below, the other protobuf options are not very far off from one to another as well
- Size : ImplicitFields seems to be the smallest in size, although it’s not far off to other options, although the run time compiled model option seems to be on the higher end.
Please note that this benchmark below is purely for my curiosity purpose, please do NOT refer this as a guidelines for any of your application.
The main reason why I’m saying the above is because I actually found somewhat different statistics when I tried to run this on the real class/model being used in my project.
The performance is somewhat as below between, however the size was the quite surprising factor where the memory size for the run time registration was 50% higher than the annotation option hence we ended up sticking up with the full annotation option as size is a very important factor as we need to send the data through the wire hence any significant size increase will introduce latency.
So again, moral of the story, please ALWAYS run a benchmark using your real project before jumping into any conclusion.
Attached the sample project again below for reference as usual.
-------------------------------
TestProtobufPreCompiledTypeModel
100 items, Size: 238905, Completed: 30 ms, Serialization: 6 ms, Deserialization: 13 ms
1000 items, Size: 2389006, Completed: 378 ms, Serialization: 69 ms, Deserialization: 161 ms
10000 items, Size: 23890006, Completed: 4195 ms, Serialization: 675 ms, Deserialization: 1806 ms
-------------------------------
TestProtobufRuntimeRegistrationWithCompiledTypeModel
100 items, Size: 273805, Completed: 42 ms, Serialization: 7 ms, Deserialization: 24 ms
1000 items, Size: 2738006, Completed: 424 ms, Serialization: 76 ms, Deserialization: 191 ms
10000 items, Size: 27380006, Completed: 4634 ms, Serialization: 762 ms, Deserialization: 2151 ms
-------------------------------
TestProtobufRuntimeRegistration
100 items, Size: 238000, Completed: 35 ms, Serialization: 8 ms, Deserialization: 16 ms
1000 items, Size: 2380000, Completed: 415 ms, Serialization: 78 ms, Deserialization: 173 ms
10000 items, Size: 23800000, Completed: 4692 ms, Serialization: 785 ms, Deserialization: 2182 ms
-------------------------------------
TestProtobufImplicitAnnotatedEntities
100 items, Size: 237700, Completed: 35 ms, Serialization: 7 ms, Deserialization: 17 ms
1000 items, Size: 2377000, Completed: 429 ms, Serialization: 78 ms, Deserialization: 201 ms
10000 items, Size: 23770000, Completed: 4799 ms, Serialization: 796 ms, Deserialization: 2207 ms
----------------------------------
TestProtobufFullyAnnotatedEntities
100 items, Size: 238900, Completed: 33 ms, Serialization: 8 ms, Deserialization: 14 ms
1000 items, Size: 2389000, Completed: 423 ms, Serialization: 79 ms, Deserialization: 166 ms
10000 items, Size: 23890000, Completed: 4734 ms, Serialization: 782 ms, Deserialization: 2243 ms
------------------
TestBinaryEntities
100 items, Size: 426909, Completed: 82 ms, Serialization: 30 ms, Deserialization: 36 ms
1000 items, Size: 4183509, Completed: 1537 ms, Serialization: 384 ms, Deserialization: 997 ms
10000 items, Size: 41749512, Completed: 89895 ms, Serialization: 4173 ms, Deserialization: 83900 ms
Run time initialisation of protobuf-net v2 without annotation
I have been using protobuf-net for the project at office but it’s only implemented for a limited number of entities (or business objects). We’re now trying to see how to implement this to the whole entities that we’re sending back n forth between the UI and the back end.
As we’re currently using a code generation “tool” to produce the code, we’re thinking to incorporate the annotation/attribute into the generated class/property code, however due to some not really technical reason, this is a bit complicated to achieve.
I thought of checking the site again to get some idea and I came across to this statement “allow use without attributes if you wish” on the page.
Then I tried to dig out more on the SO and found some more good leads on this. Apparently it’s very much possible to perform “registration” during run time mode which allows us NOT to use any annotation on the entities.
So thanks to the pointers, there are 2 alternatives for this:
1. With very minimal annotation on the class level
[ProtoContract(ImplicitFields = ImplicitFields.AllPublic)] // only required on the class level
class PersonEntity
{
public string FirstName { get; set; }
public string LastName { get; set; }
}
2. Without any annotation (using RuntimeTypeModel)
static void InitializeProtobufRunTime()
{
var assembly = Assembly.GetAssembly(typeof(PlainEntities.PersonEntity));
var types = assembly.GetTypes();
foreach (var t in types.Where(x => x.Namespace.Contains("PlainEntities")))
{
Console.WriteLine("Processing {0}", t.FullName);
var meta = RuntimeTypeModel.Default.Add(t, false);
var index = 1;
// find any derived class for the entity
foreach (var d in types.Where(x => x.IsSubclassOf(t)))
{
var i = index++;
Console.WriteLine("\tSubtype: {0} - #{1}", d.Name, i);
meta.AddSubType(i, d);
}
// then add the properties
foreach (var p in t.GetProperties(BindingFlags.Instance | BindingFlags.Public | BindingFlags.DeclaredOnly).Where(x => x.GetSetMethod() != null))
{
var i = index++;
Console.WriteLine("\tProperty: {0} - #{1}", p.Name, i);
meta.AddField(i, p.Name);
}
}
}
And both the above works quite well without any performance differences.
------------------
TestBinaryEntities
------------------
Process: 100000 items, MemorySize: 7400705, Completed in: 3877 ms, Serialization took: 676 ms, Deserialization took: 2948 ms
----------------------------------
TestProtobufFullyAnnotatedEntities
----------------------------------
Process: 100000 items, MemorySize: 3983490, Completed in: 682 ms, Serialization took: 164 ms, Deserialization took: 253 ms
-------------------------------------
TestProtobufImplicitAnnotatedEntities
-------------------------------------
Process: 100000 items, MemorySize: 3983490, Completed in: 595 ms, Serialization took: 104 ms, Deserialization took: 210 ms
-------------------------------
TestProtobufRuntimeRegistration
-------------------------------
Processing ProtobufTestConsole.PlainEntities.BaseEntity
Subtype: PersonEntity - #1
Property: Id - #2
Property: Gender - #3
Processing ProtobufTestConsole.PlainEntities.PersonEntity
Property: FirstName - #1
Property: LastName - #2
Property: Age - #3
Process: 100000 items, MemorySize: 4083490, Completed in: 646 ms, Serialization took: 113 ms, Deserialization took: 232 ms
Looking forward to get this in :)
Also attached the sample project for reference
Sample Project
Why Task Parallel Library (TPL) = Great stuffs
I just came back to office today from a short staycation and while going through the email back logs, I saw an email from a colleague asking for my practical experience with the Task Parallel Library (TPL) so far.
I’m quite delighted to share some with him and thought of just dropping some to here as well ;)
Practical usages:
- Parallel data retrieval from different sources
This has saved significant amount of time, e.g. we have 3 data retrievals, the 1st takes 10 seconds, the 2nd takes 7 seconds and the 3rd takes 4 seconds, rather than 21 seconds sequentially, we can get all 3 results in 10 (max) now. - Parallel data submission with limited concurrency
With long running processes, we need to be careful not to overload the back end services, so when TPL comes with Limited Concurrency Task Scheduler, this becomes a life saver and we can remove all the previous code complexities to achieve the same.
Summaries:
- The Task has greatly simplified the developer’s code to be able to perform asynchronous operation which returns values where previously it’s not straight forward to achieve the same (e.g. creaging a wrapper using threadpool)
- Out of the box / It comes with the .Net 4 (directly shipped by microsoft), this very much makes TPL available for us (developers) and the users (client) without worrying a separate component to download
- More good stuffs are on the way with latest .Net 4.5 Framework
The downsides:
- Potential parallelism -> good stuff + not too good stuff, good stuff -> we don’t need to worry, not too good stuff -> there are times that we want it to happen in parallel but it’s too clever not to do parallel in heavy usage especially in low spec machine (e.g. client machine is not as good as our developer PC)
- Unit testing -> It’s not so easy to test our code if we start mixing TPL into our code, although it’s true that we should separate the logic bit from the concurrency, but in reality sometimes we end up with unnecessary code to make it testable. I do hope more improvements to come for this, there are many being discussed in stackoverflow
